python爬虫豆瓣网的模拟登录实现方法
作者:袖梨
2019-08-21
本篇文章小编给大家分享一下python爬虫豆瓣网的模拟登录实现方法,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
思路
一、想要实现登录豆瓣关键点
分析真实post地址 ----寻找它的formdata,如下图,按浏览器的F12可以找到。

实战操作
实现:模拟登录豆瓣,验证码处理,登录到个人主页就算是success
数据:没有抓取数据,此实战主要是模拟登录和处理验证码的学习。要是有需求要抓取数据,编写相关的抓取规则即可抓取内容。
登录成功展示如图:
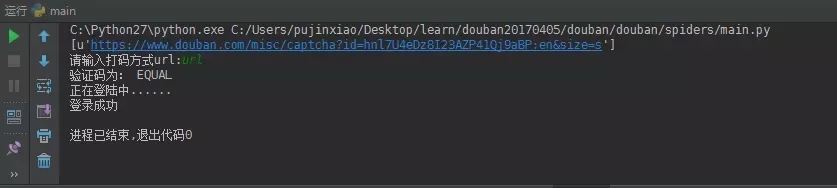
spiders文件夹中DouBan.py主要代码如下:
# -*- coding: utf-8 -*-
import scrapy,urllib,re
from scrapy.http import Request,FormRequest
import ruokuai
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class DoubanSpider(scrapy.Spider):
name = "DouBan"
allowed_domains = ["douban.com"]
#start_urls = ['http://douban.com/']
header={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"} #供登录模拟使用
def start_requests(self):
url='https://www.douban.com/accounts/login'
return [Request(url=url,meta={"cookiejar":1},callback=self.parse)]#可以传递一个标示符来使用多个。如meta={'cookiejar': 1}这句,后面那个1就是标示符
def parse(self, response):
captcha=response.xpath('//*[@id="captcha_image"]/@src').extract() #获取验证码图片的链接
print captcha
if len(captcha)>0:
'''此时有验证码'''
#人工输入验证码
#urllib.urlretrieve(captcha[0],filename="C:/Users/pujinxiao/Desktop/learn/douban20170405/douban/douban/spiders/captcha.png")
#captcha_value=raw_input('查看captcha.png,有验证码请输入:')
#用快若打码平台处理验证码--------验证码是任意长度字母,成功率较低
captcha_value=ruokuai.get_captcha(captcha[0])
reg=r'(.*?) '
reg=re.compile(reg)
captcha_value=re.findall(reg,captcha_value)[0]
print '验证码为:',captcha_value
data={
"form_email": "weisuen007@163.com",
"form_password": "weijc7789",
"captcha-solution": captcha_value,
#"redir": "https://www.douban.com/people/151968962/", #设置需要转向的网址,由于我们需要爬取个人中心页,所以转向个人中心页
}
else:
'''此时没有验证码'''
print '无验证码'
data={
"form_email": "weisuen007@163.com",
"form_password": "weijc7789",
#"redir": "https://www.douban.com/people/151968962/",
}
print '正在登陆中......'
####FormRequest.from_response()进行登陆
return [
FormRequest.from_response(
response,
meta={"cookiejar":response.meta["cookiejar"]},
headers=self.header,
formdata=data,
callback=self.get_content,
)
]
def get_content(self,response):
title=response.xpath('//title/text()').extract()[0]
if u'登录豆瓣' in title:
print '登录失败,请重试!'
else:
print '登录成功'
'''
可以继续后续的爬取工作
'''
ruokaui.py代码如下:
我所用的是若块打码平台,选择url识别验证码,直接给打码平台验证码图片的链接地址,传回验证码的值。
# -*- coding: utf-8 -*-
import sys, hashlib, os, random, urllib, urllib2
from datetime import *
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class APIClient(object):
def http_request(self, url, paramDict):
post_content = ''
for key in paramDict:
post_content = post_content + '%s=%s&'%(key,paramDict[key])
post_content = post_content[0:-1]
#print post_content
req = urllib2.Request(url, data=post_content)
req.add_header('Content-Type', 'application/x-www-form-urlencoded')
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, post_content)
return response.read()
def http_upload_image(self, url, paramKeys, paramDict, filebytes):
timestr = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
boundary = '------------' + hashlib.md5(timestr).hexdigest().lower()
boundarystr = 'rn--%srn'%(boundary)
bs = b''
for key in paramKeys:
bs = bs + boundarystr.encode('ascii')
param = "Content-Disposition: form-data; name="%s"rnrn%s"%(key, paramDict[key])
#print param
bs = bs + param.encode('utf8')
bs = bs + boundarystr.encode('ascii')
header = 'Content-Disposition: form-data; name="image"; filename="%s"rnContent-Type: image/gifrnrn'%('sample')
bs = bs + header.encode('utf8')
bs = bs + filebytes
tailer = 'rn--%s--rn'%(boundary)
bs = bs + tailer.encode('ascii')
import requests
headers = {'Content-Type':'multipart/form-data; boundary=%s'%boundary,
'Connection':'Keep-Alive',
'Expect':'100-continue',
}
response = requests.post(url, params='', data=bs, headers=headers)
return response.text
def arguments_to_dict(args):
argDict = {}
if args is None:
return argDict
count = len(args)
if count <= 1:
print 'exit:need arguments.'
return argDict
for i in [1,count-1]:
pair = args[i].split('=')
if len(pair) < 2:
continue
else:
argDict[pair[0]] = pair[1]
return argDict
def get_captcha(image_url):
client = APIClient()
while 1:
paramDict = {}
result = ''
act = raw_input('请输入打码方式url:')
if cmp(act, 'info') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
result = client.http_request('http://api.ruokuai.com/info.xml', paramDict)
elif cmp(act, 'register') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
paramDict['email'] = raw_input('email:')
result = client.http_request('http://api.ruokuai.com/register.xml', paramDict)
elif cmp(act, 'recharge') == 0:
paramDict['username'] = raw_input('username:')
paramDict['id'] = raw_input('id:')
paramDict['password'] = raw_input('password:')
result = client.http_request('http://api.ruokuai.com/recharge.xml', paramDict)
elif cmp(act, 'url') == 0:
paramDict['username'] = '********'
paramDict['password'] = '********'
paramDict['typeid'] = '2000'
paramDict['timeout'] = '90'
paramDict['softid'] = '76693'
paramDict['softkey'] = 'ec2b5b2a576840619bc885a47a025ef6'
paramDict['imageurl'] = image_url
result = client.http_request('http://api.ruokuai.com/create.xml', paramDict)
elif cmp(act, 'report') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
paramDict['id'] = raw_input('id:')
result = client.http_request('http://api.ruokuai.com/create.xml', paramDict)
elif cmp(act, 'upload') == 0:
paramDict['username'] = '********'
paramDict['password'] = '********'
paramDict['typeid'] = '2000'
paramDict['timeout'] = '90'
paramDict['softid'] = '76693'
paramDict['softkey'] = 'ec2b5b2a576840619bc885a47a025ef6'
paramKeys = ['username',
'password',
'typeid',
'timeout',
'softid',
'softkey'
]
from PIL import Image
imagePath = raw_input('Image Path:')
img = Image.open(imagePath)
if img is None:
print 'get file error!'
continue
img.save("upload.gif", format="gif")
filebytes = open("upload.gif", "rb").read()
result = client.http_upload_image("http://api.ruokuai.com/create.xml", paramKeys, paramDict, filebytes)
elif cmp(act, 'help') == 0:
print 'info'
print 'register'
print 'recharge'
print 'url'
print 'report'
print 'upload'
print 'help'
print 'exit'
elif cmp(act, 'exit') == 0:
break
return result













